データ分析の世界では、私たちが直面する情報の量は膨大です。そんな中で「PCA主成分分析」は、データの次元を削減し、重要な情報を抽出する強力な手法です。この手法を使うことで、複雑なデータセットをシンプルにし、視覚化や解釈を容易にします。
PCA 主 成分 分析とは
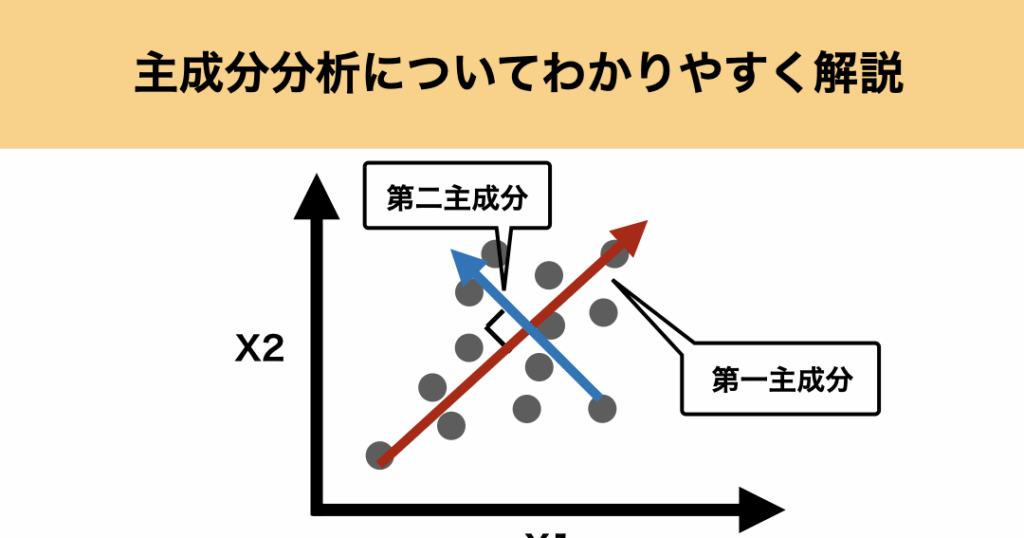
PCA主成分分析は、データ分析において重要な手法です。この手法は、データの次元を削減し、情報の可視化や解釈を助けます。
基本的な概念
PCAは、観測データの相関関係を解析することにより、データ内の重要な構造を見つけるために利用されます。具体的には、以下のプロセスが含まれます。
- データの標準化:全てのデータポイントが同じスケールで測定されるようにします。
- 共分散行列の計算:データセット内での変数間の相関を調べます。
- 固有値と固有ベクトルの取得:共分散行列から、主成分を特定します。
- 新しい特徴空間への射影:データポイントを主成分に投影し、次元を削減します。
このようにして、PCAは多次元データの重要な情報を保持しつつ、データの複雑さを軽減します。
目的と利点
PCA主成分分析の目的は、次のような利点を活かすことです。
- 情報の圧縮:データセットの情報量を減少させ、分析が容易になります。
- 可視化の向上:人間が理解しやすい形式でデータを表示できるため、効果的なプレゼンテーションの手助けになります。
- ノイズの除去:重要な情報を維持しながら、データセット内のノイズを削減できます。
- 機械学習の前処理:モデルの性能向上や学習時間を短縮するために、事前処理として使われることが多いです。
PCAの数学的背景
PCAの背景には、行列計算と線形代数に基づく理論が存在する。データの次元を削減し、重要な情報を抽出する過程を理解するためには、まず行列の対角化を理解する必要がある。
行列の対角化
行列の対角化とは、正方行列を対角行列に変換する過程を指す。この変換により、行列の性質を簡単に解析することができる。具体的には、行列Aが固有値λを持つ固有ベクトルvを用いて、次のように表せる。
- Av = λv
この式により、行列の計算が容易になり、特にデータの共分散行列を利用する際に役立つ。実際、PCAではデータの共分散行列の対角化を行い、データの主要な成分を抽出することができる。
固有値と固有ベクトル
固有値と固有ベクトルは、PCAの根幹を成す概念である。まず、固有値は行列の特性を示し、固有ベクトルはそれに対応する方向を示す。固有値が大きいほど、その成分はデータに対する重要性が高い。これらの関係式は次のように表される。
- A v = λ v
PCAの実用例
PCA主成分分析は、様々な分野で重要な役割を果たします。この手法の利用例をいくつか見ていきましょう。
データの次元削減
データの次元削減は、PCAの最も一般的な応用の一つです。複数の変数を含むデータセットでは、重要な情報を抽出しながら、次元を削減することが可能です。たとえば、顧客の購買データに対してPCAを適用することで、主要な購買パターンを特定でき、データ分析が効率的になります。また、次元削減により、計算コストが減少し、さらに機械学習アルゴリズムの性能が向上することが確認されています。
PCAの実装
PCAの実装は、主要なライブラリを使用して簡単に行える。これにより、データ分析のプロセスがスムーズに進む。以下に、PCAを実行するために一般的に使用されるライブラリを示す。
使用するライブラリ
- NumPy: 数値計算を効率的に行えるライブラリ。行列の演算とデータ操作に最適。
- Pandas: データの読み込み、操作、分析を簡単にするためのツール。データフレーム構造を持ち、データ管理が直感的。
- scikit-learn: 機械学習のための包括的なライブラリ。特にPCAの実装が簡単で、多様な機能が提供されている。
- Matplotlib: グラフ描画のためのライブラリ。PCAの結果を視覚化するのに理想的。
コード例
以下のコードは、PCAを実装する際の基本的な流れを示している。これにより、データの次元削減が可能になる。
import numpy as np
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# データの読み込み
data = pd.read_csv('data.csv')
# データの標準化
standardized_data = (data - data.mean()) / data.std()
# PCAの適用
pca = PCA(n_components=2) # 2次元に削減
principal_components = pca.fit_transform(standardized_data)
# 結果のデータフレーム作成
principal_df = pd.DataFrame(data=principal_components, columns=['主成分1', '主成分2'])
# グラフの描画
plt.scatter(principal_df['主成分1'], principal_df['主成分2'])
plt.xlabel('主成分1')
plt.ylabel('主成分2')
plt.title('PCA結果')
plt.show()
注意点と限界
PCA主成分分析には、いくつかの注意点や限界があります。これらを理解することで、正しく効果的に利用することができます。
データの前処理
データの前処理が重要です。情報の質が結果に直接影響を与えるため、データを適切に整えることが必要です。具体的には、以下の点に留意します。
- 欠損値の処理:欠損値が存在すると、正確な結果が得られない可能性があります。適切な方法で補完や除外を行います。
- 標準化の実施:異なるスケールの変数を持つ場合、標準化が不可欠です。平均を0、標準偏差を1にすることで、変数間のバランスを保ちます。
- 外れ値の影響:外れ値も分析に悪影響を及ぼすことがあります。適切に検出し、処理することで安定した結果が得られます。
解釈の難しさ
解釈が難しい結果もあります。PCAによって得られる主成分は、元の変数の組み合わせであるため、それぞれの意味が直感的に理解しづらくなることがあります。具体的な課題には、以下が含まれます。
- 成分の意義:得られた主成分が何を表しているのか、明確に理解するのが難しい場合があります。専門知識が必要になります。
- 次元削減の情報喪失:次元を削減すると、重要な情報が失われる可能性があります。結果として、意思決定において誤った方向に進むおそれがあります。
- 変数間の関連性:主成分が変数のどのような関係を明示するか、一つの示唆では理解しきれないことがあります。これにより、分析結果の正確性が脅かされることもあります。
Conclusion
PCA主成分分析はデータ分析の強力なツールであり私たちの理解を深める手助けをしてくれます。この手法を利用することでデータの次元を削減し重要な情報を抽出することが可能です。実装も容易であり主要なライブラリを活用することで効率的なデータ処理が実現します。
ただし注意が必要な点もあります。データの前処理や主成分の解釈には慎重さが求められます。これらを理解し適切に対処することでPCAの利点を最大限に引き出せるでしょう。私たちがこの手法を活用することでデータ分析の新たな可能性を見出すことができるのです。